Developer Guide
In general we prefer simplicity. We standardize on JavaScript (Node.js) and SQL (PostgreSQL) as the languages of implementation and try to minimize the number of complex libraries or frameworks being used. The website is server-side generated pages with minimal client-side JavaScript.
High level view
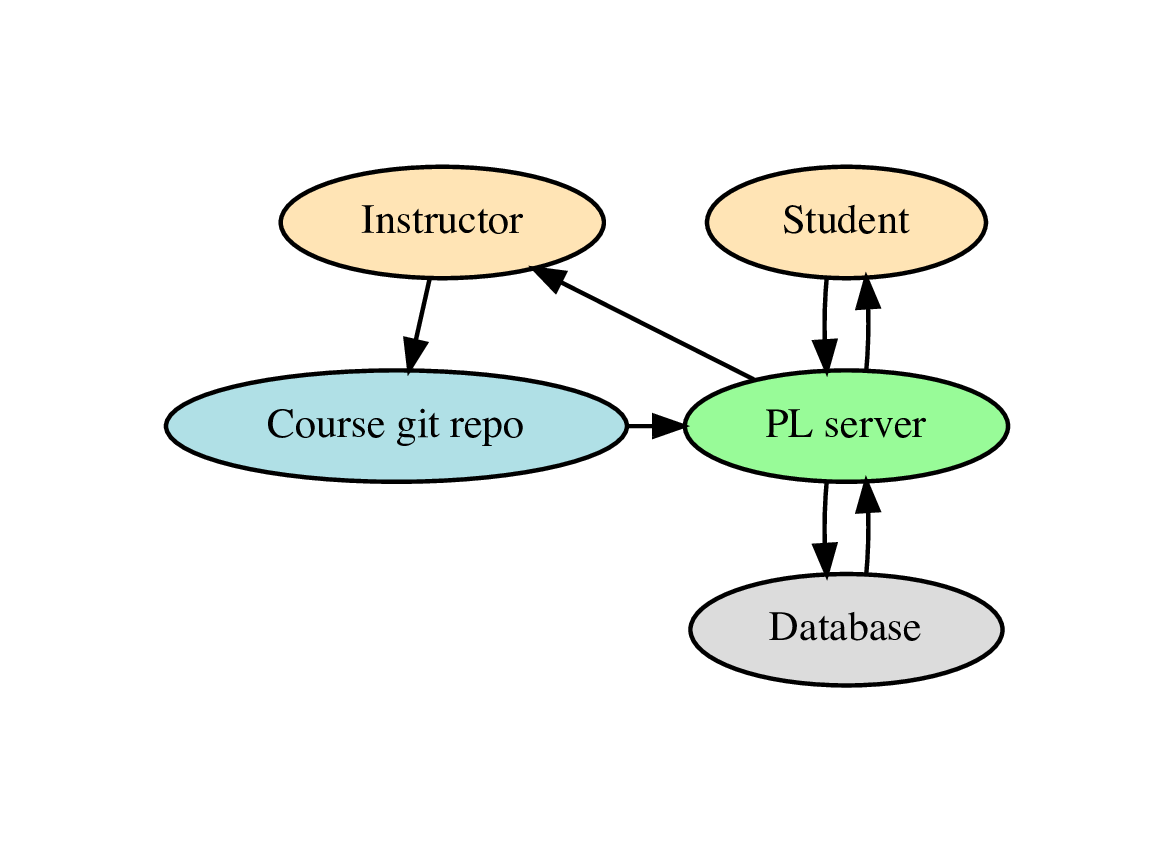
- The questions and assessments for a course are stored in a git repository. This is synced into the database by the course instructor and DB data is updated or added to represent the course. Students then interact with the course website by doing questions, with the results being stored in the DB. The instructor can view the student results on the website and download CSV files with the data.
- All course configuration is done via plain text files in the git repository, which is the master source for this data. There is no extra course configuration stored in the DB. The instructor does not directly edit course data via the website.
- All student data is all stored in the DB and is not pushed back into the git repository or disk at any point.
Directory layout
- Broadly follow the Express generator layout.
-
Top-level files and directories are:
PrairieLearn +-- autograder # files needed to autograde code on a separate server | `-- ... # various scripts and docker images +-- config.json # server configuration file (optional) +-- cron # jobs to be periodically executed, one file per job | +-- index.js # entry point for all cron jobs | `-- ... # one JS file per cron job, executed by index.js +-- docs # documentation +-- exampleCourse # example content for a course +-- lib # miscellaneous helper code +-- middlewares # Express.js middleware, one per file +-- migrations # DB migrations | +-- ... # one PGSQL file per migration, executed in order of their timestamp +-- package.json # JavaScript package manifest +-- pages # one sub-dir per web page | +-- partials # EJS helper sub-templates | +-- instructorHome # all the code for the instructorHome page | +-- userHome # all the code for the userHome page | `-- ... # other "instructor" and "user" pages +-- public # all accessible without access control | +-- javascripts # external packages only, no modifications | +-- localscripts # all local site-wide JS | `-- stylesheets # all CSS, both external and local +-- question-servers # one file per question type +-- server.js # top-level program +-- sprocs # DB stored procedures, one per file | +-- index.js # entry point for all sproc initialization | `-- ... # one JS file per sproc, executed by index.js +-- sync # code to load on-disk course config into DB `-- tests # unit and integration tests
Unit tests and integration tests
- Tests are stored in the
tests/directory and listed intests/index.js.
- To run the tests during development, see Running the test suite.
- The tests are run by the CI server on every push to GitHub.
- The tests are mainly integration tests that start with a blank database, run the server to initialize the database, load the
testCourse, and then emulate a client web browser that answers questions on assessments. If a test fails then it is often easiest to debug by recreating the error by doing questions yourself against a locally-running server.
- If the
PL_KEEP_TEST_DBenvironment is set, the test database (normallypltest) won't be DROP'd when testing ends. This allows you inspect the state of the database whenever your testing ends. The database will get overwritten when you start a new test.
Debugging server-side JavaScript
-
Use the debug package to help trace execution flow in JavaScript. To run the server with debugging output enabled:
DEBUG=* make dev
-
To just see debugging logs from PrairieLearn you can use:
DEBUG=prairielearn:* make dev
-
To insert more debugging output, import
debugand use it like this:import debugfn from 'debug'; const debug = debugfn('prairielearn:my-file'); // in some function later debug('func()', 'param:', param);
- As of 2017-08-08 we don't have very good coverage with debug output in code, but we are trying to add more as needed, especially in code in
lib/.
UnhandledPromiseRejectionWarningerrors are frequently due to improper async/await handling. Make sure you are calling async functions withawait, and that async functions are not being called from callback-style code without acallbackify(). To get more information, Node >= 14 can be run with the--trace-warningsflag. For example,node_modules/.bin/mocha --trace-warnings tests/index.js.
Debugging client-side JavaScript
- Make sure you have the JavaScript Console open in your browser and reload the page.
Debugging SQL and PL/pgSQL
-
Use the
psqlcommandline interface to test SQL separately. A default development PrairieLearn install uses thepostgresdatabase, so you should run:psql postgres
- To debug syntax errors in a stored procedure, import it manually with
\i filename.sqlinpsql.
-
To follow execution flow in PL/pgSQL use
RAISE NOTICE. This will log to the console when run frompsqland to the server log file when run from within PrairieLearn. The syntax is:RAISE NOTICE 'This is logging: % and %', var1, var2;
-
To manually run a function:
SELECT the_sql_function (arg1, arg2);
HTML page generation
- Use Express as the web framework.
- All pages are server-side rendered and we try and minimize the amount of client-side JavaScript. Client-side JS should use jQuery and related libraries. We prefer to use off-the-shelf jQuery plugins where possible.
-
Each web page typically has all its files in a single directory, with the directory, the files, and the URL all named the same. Not all pages need all files. For example:
pages/instructorGradebook +-- instructorGradebook.js # main entry point, calls the SQL and renders the template +-- instructorGradebook.sql # all SQL code specific to this page +-- instructorGradebook.ejs # the EJS template for the page `-- instructorGradebookClient.js # any client-side JS needed
-
The above
instructorGradebookpage is loaded from the top-levelserver.jswith:app.use( '/instructor/:courseInstanceId/gradebook', require('./pages/instructorGradebook/instructorGradebook'), );
-
The
instructorGradebook.jsmain JS file is an Expressrouterand has the basic structure:var ERR = require('async-stacktrace'); var _ = require('lodash'); var express = require('express'); var router = express.Router(); var sqldb = require('@prairielearn/postgres'); var sql = sqldb.loadSqlEquiv(__filename); router.get('/', function (req, res, next) { var params = { course_instance_id: res.params.courseInstanceId }; sqldb.query(sql.user_scores, params, function (err, result) { // SQL queries for page data if (ERR(err, next)) return; res.locals.user_scores = result.rows; // store the data in res.locals res.render('pages/instructorGradebook/instructorGradebook', res.locals); // render the page // inside the EJS template, "res.locals.var" can be accessed with just "var" }); }); module.exports = router;
- Use the
res.localsvariable to build up data for the page rendering. Many basic objects are already included from theselectAndAuthz*.jsmiddleware that runs before most page loads.
- Use EJS templates (Embedded JavaScript) templates for all pages. Using JS as the templating language removes the need for another ad hoc language, but does require some discipline to not get in a mess. Try and minimize the amount of JS code in the template files. Inside a template the JS code can directly access the contents of the
res.localsobject.
-
Sub-templates are stored in
pages/partialsand can be loaded as below. The sub-template can also accessres.localsas its base scope, and can also accept extra arguments with an arguments object:<%- include('../partials/assessment', {assessment: assessment}); %>
HTML style
- Use Bootstrap as the style. As of 2019-12-13 we are using v4.
- Local CSS rules go in
public/stylesheets/local.css. Try to minimize use of this and use plain Bootstrap styling wherever possible.
- Buttons should use the
<button>element when they take actions and the<a>element when they are simply links to other pages. We should not use<a role="button">to fake a button element. Buttons that do not submit a form should always start with<button type="button" class="btn ...">, wheretype="button"specifies that they don't submit.
SQL usage
- Use PostgreSQL and feel free to use the latest features.
- The PostgreSQL manual is an excellent reference.
- Write raw SQL rather than using a ORM library. This reduces the number of frameworks/languages needed.
- Try and write as much code in SQL and PL/pgSQL as possible, rather than in JavaScript. Use PostgreSQL-specific SQL and don't worry about SQL dialect portability. Functions should be written as stored procedures in the
sprocs/directory.
- The
sprocs/directory has files that each contain exactly one stored procedure. The filename is the same as the name of the stored procedure, so thevariants_insert()stored procedure is in thesprocs/variants_insert.sqlfile.
- Stored procedure names should generally start with the name of the table they are associated with and try to use standard SQL command names to describe what they do. For example,
variants_insert()will do some kind ofINSERT INTO variants, whilesubmission_update_parsing()will do anUPDATE submissionswith some parsing data.
- Use the SQL convention of
snake_casefor names. Also use the same convention in JavaScript for names that are the same as in SQL, so thequestion_idvariable in SQL is also calledquestion_idin JavaScript code.
- Use uppercase for SQL reserved words like
SELECT,FROM,AS, etc.
-
SQL code should not be inline in JavaScript files. Instead it should be in a separate
.sqlfile, following the Yesql concept. Eachfilename.jsfile will normally have a correspondingfilename.sqlfile in the same directory. The.sqlfile should look like:-- BLOCK select_question SELECT * FROM questions WHERE id = $question_id; -- BLOCK insert_submission INSERT INTO submissions (submitted_answer) VALUES ($submitted_answer) RETURNING *;
From JavaScript you can then do:
var sqldb = require('@prairielearn/postgres');
var sql = sqldb.loadSqlEquiv(__filename); // from filename.js will load filename.sql
// run the entire contents of the SQL file
sqldb.query(sql.all, params, ...);
// run just one query block from the SQL file
sqldb.query(sql.select_question, params, ...);-
The layout of the SQL code should generally have each list in separate indented blocks, like:
SELECT ft.col1, ft.col2 AS renamed_col, st.col1 FROM first_table AS ft JOIN second_table AS st ON (st.first_table_id = ft.id) WHERE ft.col3 = select3 AND st.col2 = select2 ORDER BY ft.col1;
-
To keep SQL code organized it is a good idea to use CTEs (
WITHqueries). These are formatted like:WITH first_preliminary_table AS ( SELECT -- first preliminary query ), second_preliminary_table AS ( SELECT -- second preliminary query ) SELECT -- main query here FROM first_preliminary_table AS fpt, second_preliminary_table AS spt;
DB stored procedures (sprocs)
-
Stored procedures are created by the files in
sprocs/. To call a stored procedure from JavaScript, use code like:const workspace_id = 1342; const message = 'Startup successful'; sqldb.call('workspaces_message_update', [workspace_id, message], (err, result) => { if (ERR(err, callback)) return; // we could use the result here if we want the return value of the stored procedure callback(null); });
- The stored procedures are all contained in a separate database schema with a name like
server_2021-07-07T20:25:04.779Z_T75V6Y. To see a list of the schemas use the\dncommand inpsql.
-
To be able to use the stored procedures from the
psqlcommand line it is necessary to get the most recent schema name using\dnand set thesearch_pathto use this quoted schema name and thepublicschema:set search_path to "server_2021-07-07T20:25:04.779Z_T75V6Y",public;
- During startup we initially have no non-public schema in use. We first run the migrations to update all tables in the
publicschema, then we callsqldb.setRandomSearchSchemaAsync()to activate a random per-execution schema, and we run the sproc creation code to generate all the stored procedures in this schema. This means that every invocation of PrairieLearn will have its own locally-scoped copy of the stored procedures which are the correct versions for its code. This lets us upgrade PrairieLearn servers one at a time, while old servers are still running with their own copies of their sprocs. When PrairieLearn first starts up it hassearch_path = public, but later it will havesearch_path = "server_2021-07-07T20:25:04.779Z_T75V6Y",publicso that it will first search the random schema and then fall back topublic. The naming convention for the random schema uses the local instance name, the date, and a random string. Note that schema names need to be quoted using double-quotations inpsqlbecause they contain characters such as hyphens.
- For more details see
sprocs/array_and_number.sqland comments inserver.jsnear the call tosqldb.setRandomSearchSchemaAsync().
DB schema (simplified overview)
- The most important tables in the database are shown in the diagram below (also as a PDF image).
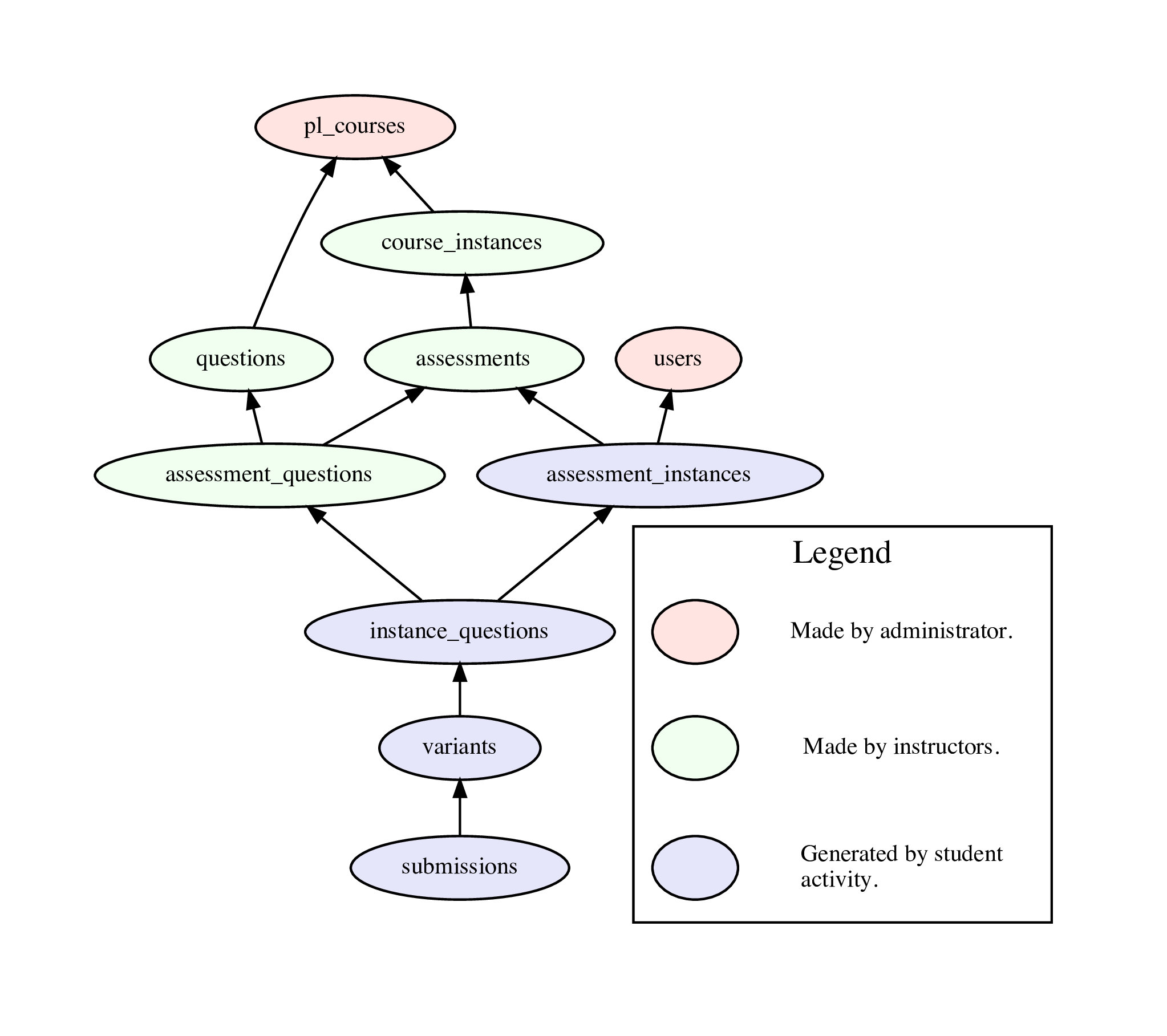
- Detailed descriptions of the format of each table are in the list of DB tables.
- Each table has an
idnumber that is used for cross-referencing. For example, each row in thequestionstable has anidand other tables will refer to this as aquestion_id. The only exceptions are thepl_coursestable that other tables refer to withcourse_idanduserswhich has auser_id. These are both for reasons of interoperability with PrairieSchedule.
- Each student is stored as a single row in the
userstable.
- The
pl_coursestable has one row for each course, likeTAM 212.
- The
course_instancestable has one row for each semester (“instance”) of each course, with thecourse_idindicating which course it belongs to.
- Every question is a row in the
questionstable, and thecourse_idshows which course it belongs to. All the questions for a course can be thought of as the “question pool” for that course. This same pool is used for all semesters (all course instances).
- Assessments are stored in the
assessmentstable and each assessment row has acourse_instance_idto indicate which course instance (and hence which course) it belongs to. An assessment is something like “Homework 1” or “Exam 3”. To determine this we can use theassessment_set_idandnumberof each assessment row.
- Each assessment has a list of questions associated with it. This list is stored in the
assessment_questionstable, where each row has aassessment_idandquestion_idto indicate which questions belong to which assessment. For example, there might be 20 different questions that are on “Exam 1”, and it might be the case that each student gets 5 of these questions randomly selected.
- Each student will have their own copy of an assessment, stored in the
assessment_instancestable with each row having auser_idandassessment_id. This is where the student's score for that assessment is stored.
- The selection of questions that each student is given on each assessment is in the
instance_questionstable. Here each row has anassessment_question_idand anassessment_instance_idto indicate that the corresponding question is on that assessment instance. This row will also store the student's score on this particular question.
- Questions can randomize their parameters, so there are many possible variants of each question. These are stored in the
variantstable with aninstance_question_idindicating which instance question the variant belongs to.
- For each variant of a question that a student sees they will have submitted zero or more
submissionswith avariant_idto show what it belongs to. The submissions row also contains information the submitted answer and whether it was correct.
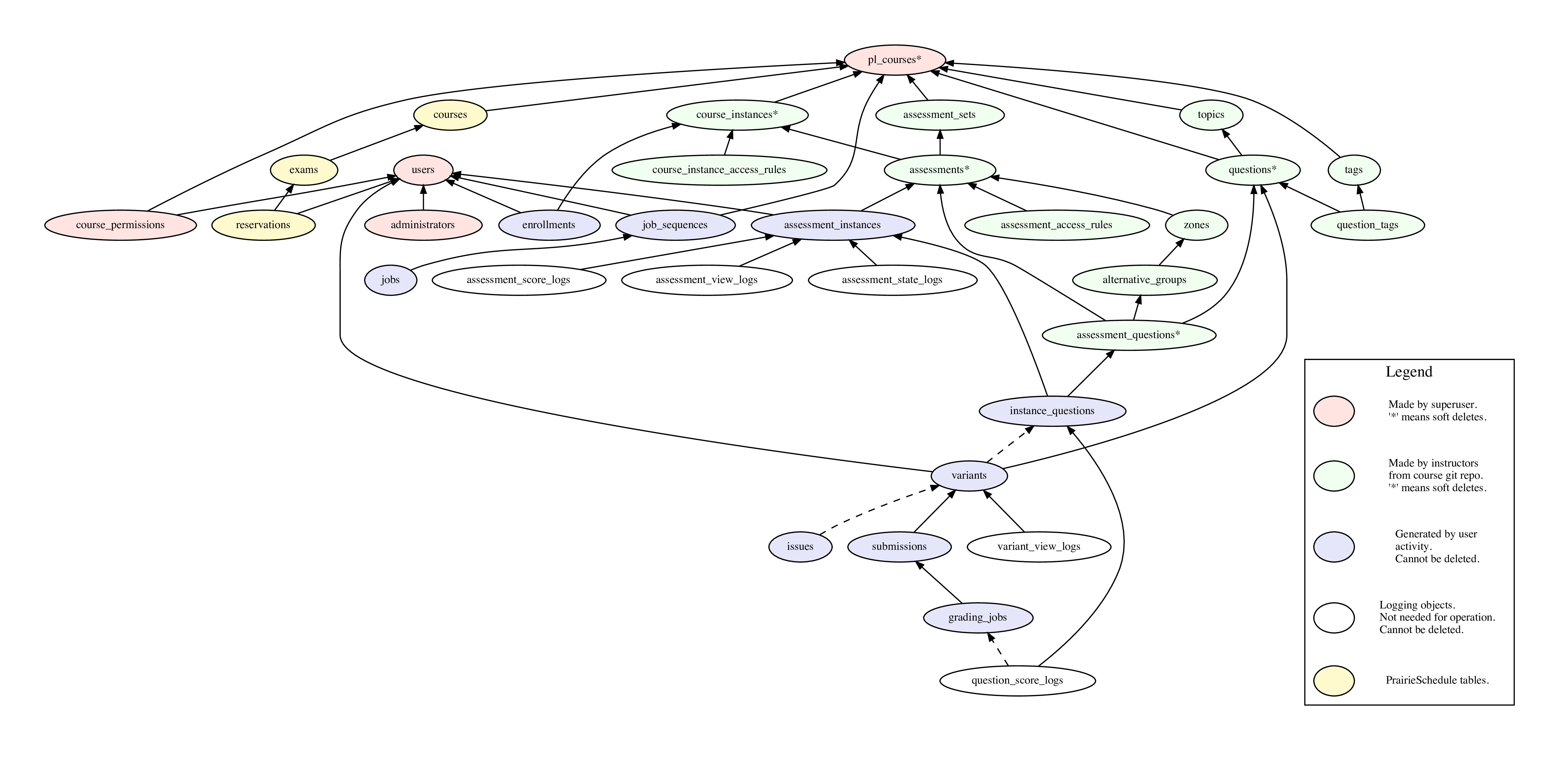
DB schema (full data)
- See the list of DB tables, with the ER (entity relationship) diagram below (PDF ER diagram).
DB schema conventions
-
Tables have plural names (e.g.
assessments) and always have a primary key calledid. The foreign keys pointing to this table are non-plural, likeassessment_id. When referring to this use an abbreviation of the first letters of each word, likeaiin this case. The only exceptions areasetforassessment_sets(to avoid conflicting with the SQLASkeyword),topfortopics, andtagfortags(to avoid conflicts). This gives code like:-- select all active assessment_instances for a given assessment SELECT ai.* FROM assessments AS a JOIN assessment_instances AS ai ON (ai.assessment_id = a.id) WHERE a.id = 45 AND ai.deleted_at IS NULL;
- We (almost) never delete student data from the DB. To avoid having rows with broken or missing foreign keys, course configuration tables (e.g.
assessments) can't be actually deleted. Instead they are "soft-deleted" by setting thedeleted_atcolumn to non-NULL. This means that when using any soft-deletable table we need to have aWHERE deleted_at IS NULLto get only the active rows.
DB schema modification
JSON syncing
-
Edit the DB schema; e.g., to add a
require_honor_codeboolean for assessments, modifydatabase/tables/assessments.pg:@@ -16,2 +16,3 @@ columns order_by: integer + require_honor_code: boolean default true shuffle_questions: boolean default false
-
Add a DB migration; e.g., create
migrations/167_assessments__require_honor_code__add.sql:@@ -0,0 +1 @@ +ALTER TABLE assessments ADD COLUMN require_honor_code boolean DEFAULT true;
-
Edit the JSON schema; e.g., modify
schemas/schemas/infoAssessment.json:@@ -89,2 +89,7 @@ "default": true + }, + "requireHonorCode": { + "description": "Requires the student to accept an honor code before starting exam assessments.", + "type": "boolean", + "default": true }
-
Edit the sync parser; e.g., modify
sync/fromDisk/assessments.js:@@ -44,2 +44,3 @@ function buildSyncData(courseInfo, courseInstance, questionDB) { const allowRealTimeGrading = !!_.get(assessment, 'allowRealTimeGrading', true); + const requireHonorCode = !!_.get(assessment, 'requireHonorCode', true); @@ -63,2 +64,3 @@ function buildSyncData(courseInfo, courseInstance, questionDB) { allow_real_time_grading: allowRealTimeGrading, + require_honor_code: requireHonorCode, auto_close: !!_.get(assessment, 'autoClose', true),
-
Edit the sync query; e.g., modify
sprocs/sync_assessments.sql:@@ -44,3 +44,4 @@ BEGIN allow_issue_reporting, - allow_real_time_grading) + allow_real_time_grading, + require_honor_code) ( @@ -64,3 +65,4 @@ BEGIN (assessment->>'allow_issue_reporting')::boolean, - (assessment->>'allow_real_time_grading')::boolean + (assessment->>'allow_real_time_grading')::boolean, + (assessment->>'require_honor_code')::boolean ) @@ -83,3 +85,4 @@ BEGIN allow_issue_reporting = EXCLUDED.allow_issue_reporting, - allow_real_time_grading = EXCLUDED.allow_real_time_grading + allow_real_time_grading = EXCLUDED.allow_real_time_grading, + require_honor_code = EXCLUDED.require_honor_code WHERE
-
Edit the sync tests; e.g., modify
tests/sync/util.js:@@ -128,2 +128,3 @@ const syncFromDisk = require('../../sync/syncFromDisk'); * @property {boolean} allowRealTimeGrading + * @property {boolean} requireHonorCode * @property {boolean} multipleInstance
- Add documentation; e.g., the honor code option is described at Assessments -- Honor code.
- Add tests.
Database access
- DB access is via the
sqldb.jsmodule. This wraps the node-postgres library.
-
For single queries we normally use the following pattern, which automatically uses connection pooling from node-postgres and safe variable interpolation with named parameters and prepared statements:
var params = { course_id: 45, }; sqldb.query(sql.select_questions_by_course, params, function (err, result) { if (ERR(err, callback)) return; var questions = result.rows; });
Where the corresponding filename.sql file contains:
-- BLOCK select_questions_by_course
SELECT
*
FROM
questions
WHERE
course_id = $course_id;-
For queries where it would be an error to not return exactly one result row:
sqldb.queryOneRow(sql.block_name, params, function (err, result) { if (ERR(err, callback)) return; var obj = result.rows[0]; // guaranteed to exist and no more });
-
Use explicit row locking whenever modifying student data related to an assessment. This must be done within a transaction. The rule is that we lock either the variant (if there is no corresponding assessment instance) or the assessment instance (if we have one). It is fine to repeatedly lock the same row within a single transaction, so all functions involved in modifying elements of an assessment (e.g., adding a submission, grading, etc) should call a locking function when they start. All locking functions are equivalent in their action, so the most convenient one should be used in any given situation:
Locking function Argument assessment_instances_lockassessment_instance_idinstance_questions_lockinstance_question_idvariants_lockvariant_idsubmission_locksubmission_id
-
To pass an array of parameters to SQL code, use the following pattern, which allows zero or more elements in the array. This replaces
$points_listwithARRAY[10, 5, 1]in the SQL. It's required to specify the type of array in case it is empty:var params = { points_list: [10, 5, 1], }; sqldb.query(sql.insert_assessment_question, params, ...);-- BLOCK insert_assessment_question INSERT INTO assessment_questions (points_list) VALUES ($points_list::INTEGER[]);
-
To use a JavaScript array for membership testing in SQL use
unnest()like:var params = { id_list: [7, 12, 45], }; sqldb.query(sql.select_questions, params, ...);-- BLOCK select_questions SELECT * FROM questions WHERE id IN ( SELECT unnest($id_list::INTEGER[]) );
-
To pass a lot of data to SQL a useful pattern is to send a JSON object array and unpack it in SQL to the equivalent of a table. This is the pattern used by the "sync" code, such as sprocs/sync_news_items.sql. For example:
let data = [ {a: 5, b: "foo"}, {a: 9, b: "bar"} ]; let params = {data: JSON.stringify(data)}; sqldb.query(sql.insert_data, params, ...);-- BLOCK insert_data INSERT INTO my_table (a, b) SELECT * FROM jsonb_to_recordset($data) AS (a INTEGER, b TEXT);
-
To use a JSON object array in the above fashion, but where the order of rows is important, use
ROWS FROM () WITH ORDINALITYto generate a row index like this:-- BLOCK insert_data INSERT INTO my_table (a, b, order_by) SELECT * FROM ROWS FROM (jsonb_to_recordset($data) AS (a INTEGER, b TEXT)) WITH ORDINALITY AS data (a, b, order_by);
Asynchronous control flow in JavaScript
- New code in PrairieLearn should use async/await whenever possible.
- Older code in PrairieLearn uses the traditional Node.js error handling conventions with the
callback(err, result)pattern.
- Use the async library for complex control flow. Versions 3 and higher of
asyncsupport both async/await and callback styles.
Using async route handlers with ExpressJS
-
Express can't directly use async route handlers. Instead we use express-async-handler like this:
const asyncHandler = require('express-async-handler'); router.get( '/', asyncHandler(async (req, res, next) => { // can use "await" here }), );
Interfacing between callback-style and async/await-style functions
-
To write a callback-style function that internally uses async/await code, use this pattern:
const util = require('util'); function oldFunction(x1, x2, callback) { util.callbackify(async () => { # here we can use async/await code y1 = await f(x1); y2 = await f(x2); return y1 + y2; })(callback); }
- To write a multi-return-value callback-style function that internally uses async/await code, we don't currently have an established pattern.
-
To call our own library functions from async/await code, we should provide a version of them with "Async" appended to the name:
const util = require('util'); module.exports.existingLibFun = (x1, x2, callback) => { callback(null, x1*x2); }; module.exports.existingLibFunAsync = util.promisify(module.exports.myFun); # in `async` code we can now call existingLibFunAsync() directly with `await`: async function newFun(x1, x2) { let y = await existingLibFunAsync(x1, x2); return 3*y; }
-
If our own library functions use multiple return values, then the async version of them should return an object:
const util = require('util'); module.exports.existingMultiFun = (x, callback) => { const y1 = x*x; const y2 = x*x*x; callback(null, y1, y2); # note the two return values here }; module.exports.existingMultiFunAsync = util.promisify((x, callback) => module.exports.existingMultiFun(x, (err, y1, y2) => callback(err, {y1, y2})) ); async function newFun(x) { let {y1, y2} = await existingMultiFunAsync(x); # must use y1,y2 names here return y1*y2; }
-
To call a callback-style function in an external library from within an async/await function, use this pattern:
util = require('util'); async function g(x) { x1 = await f(x + 2); x2 = await f(x + 4); z = await util.promisify(oldFunction)(x1, x2); return z; }
-
As of 2019-08-15 we are not calling any multi-return-value callback-style functions in external libraries from within async/await functions, but if we need to do this then we could include the
bluebirdpackage and use the pattern:bluebird = require('bluebird'); function oldMultiFunction(x, callback) { return callback(null, x*x, x*x*x); } async function g(x) { let [y1, y2] = await bluebird.promisify(oldMultiFunction, {multiArgs: true})(x); # note array destructuring with y1,y2 return y1*y2; }
-
To call an async/await function from within a callback-style function, use this pattern:
util = require('util'); function oldFunction(x, callback) { util.callbackify(g)(x, (err, y) => { if (ERR(err, callback)) return; callback(null, y); }); }
-
To call an multi-return-value async/await function from within a callback-style function, use this pattern:
util = require('util'); async function gMulti(x) { y1 = x*x; y2 = x*x*x; return {y1, y2}; } function oldFunction(x, callback) { util.callbackify(gMulti)(x, (err, {y1, y2}]) => { if (ERR(err, callback)) return; callback(null, y1*y2); }); }
Stack traces with callback-style functions
-
Use the async-stacktrace library for every error handler. That is, the top of every file should have
ERR = require('async-stacktrace');and wherever you would normally writeif (err) return callback(err);you instead writeif (ERR(err, callback)) return;. This does exactly the same thing, except that it modifies theerrobject's stack trace to include the current filename/linenumber, which greatly aids debugging. For example:// Don't do this: function foo(p, callback) { bar(q, function (err, result) { if (err) return callback(err); callback(null, result); }); } // Instead do this: ERR = require('async-stacktrace'); // at top of file function foo(p, callback) { bar(q, function (err, result) { if (ERR(err, callback)) return; // this is the change callback(null, result); }); }
-
Don't pass
callbackfunctions directly through to children, but instead capture the error with the async-stacktrace library and pass it up the stack explicitly. This allows a complete stack trace to be printed on error. That is:// Don't do this: function foo(p, callback) { bar(q, callback); } // Instead do this: function foo(p, callback) { bar(q, function (err, result) { if (ERR(err, callback)) return; callback(null, result); }); }
- Note that the async-stacktrace library
ERRfunction will throw an exception if not provided with a callback, so in cases where there is no callback (e.g., incron/index.js) we should call it withERR(err, function() {}).
-
If we are in a function that does not have an active callback (perhaps we already called it) then we should log errors with the following pattern. Note that the first string argument to
logger.error()is mandatory. Failure to provide a string argument will result inerror: undefinedbeing logged to the console.function foo(p) { bar(p, function(err, result) { if (ERR(err, e => logger.error('Error in bar()', e); ... }); }
-
Don't call a
callbackfunction inside a try block, especially if there is also acallbackcall in the catch handler. Otherwise exceptions thrown much later will show up incorrectly as a double-callback or just in the wrong place. For example:// Don't do this: function foo(p, callback) { try { let result = 3; callback(null, result); // this could throw an error from upstream code in the callback } catch (err) { callback(err); } } // Instead do this: function foo(p, callback) { let result; try { result = 3; } catch (err) { callback(err); } callback(null, result); }
Security model
- We distinguish between authentication and authorization. Authentication occurs as the first stage in server response and the authenticated user data is stored as
res.locals.authn_user.
-
The authentication flow is:
-
We first redirect to a remote authentication service (either Shibboleth or Google OAuth2 servers). For Shibboleth this happens by the “Login to PL” button linking to
/pl/shibcallbackfor which Apache handles the Shibboleth redirections. For Google the “Login to PL” button links to/pl/auth2loginwhich sets up the authentication data and redirects to Google. -
The remote authentication service redirects back to
/pl/shibcallback(for Shibboleth) or/pl/auth2callback(for Google). These endpoints confirm authentication, create the user in theuserstable if necessary, set a signedpl_authncookie in the browser with the authenticateduser_id, and then redirect to the main PL homepage. This cookie is set with theHttpOnlyattribute, which prevents client-side JavaScript from reading the cookie. -
Every other page authenticates using the signed browser
pl_authncookie. This is read bymiddlewares/authn.jswhich checks the signature and then loads the user data from the DB using theuser_id, storing it asres.locals.authn_user.
-
- Similar to unix, we distinguish between the real and effective user. The real user is stored as
res.locals.authn_userand is the user that authenticated. The effective user is stored asres.locals.user. Only users withrole = TAor higher can set an effective user that is different from their real user. Moreover, users withrole = TAor higher can also set an effectiveroleandmodethat is different to the real values.
-
Authorization occurs at multiple levels:
- The
course_instancechecks authorization based on theauthn_user.
- The
course_instanceauthorization is checked against the effectiveuser.
- The
assessmentchecks authorization based on the effectiveuser,role,mode, anddate.
- The
- All state-modifying requests must (normally) be POST and all associated data must be in the body. GET requests may use query parameters for viewing options only.
State-modifying POST requests
-
Use the Post/Redirect/Get pattern for all state modification. This means that the initial GET should render the page with a
<form>that has noactionset, so it will submit back to the current page. This should be handled by a POST handler that performs the state modification and then issues a redirect back to the same page as a GET:router.post('/', function (req, res, next) { if (req.body.__action == 'enroll') { var params = { course_instance_id: req.body.course_instance_id, user_id: res.locals.authn_user.user_id, }; sqldb.queryOneRow(sql.enroll, params, function (err, result) { if (ERR(err, next)) return; res.redirect(req.originalUrl); }); } else { return next(new error.HttpStatusError(400, `unknown __action: ${req.body.__action}`)); } });
- To defeat CSRF (Cross-Site Request Forgery) we use the Encrypted Token Pattern. This stores an HMAC-authenticated token inside the POST data.
-
All data modifying requests should come from
formelements like:<form name="enroll-form" method="POST"> <input type="hidden" name="__action" value="enroll" /> <input type="hidden" name="__csrf_token" value="<%= __csrf_token %>" /> <input type="hidden" name="course_instance_id" value="56" /> <button type="submit" class="btn btn-info">Enroll in course instance 56</button> </form>
- The
res.locals.__csrf_tokenvariable is set and checked by early-stage middleware, so no explicit action is needed on each page.
Logging errors
- We use Winston for logging to the console and to files. To use this, require
lib/loggerand calllogger.info(),logger.error(), etc.
- To show a message on the console, use
logger.info().
- To log just to the log files, but not to the console, use
logger.verbose().
- All
loggerfunctions have a mandatory first argument that is a string, and an optional second argument that is an object containing useful information. It is important to always provide a string as the first argument.
Coding style
ESLint and Prettier are used to enforce consistent code conventions and formatting throughout the codebase. See .eslintrc.js and .prettierrc.json in the root of the PrairieLearn repository to view our specific configuration. The repo includes an .editorconfig file that most editors will detect and use to automatically configure things like indentation. If your editor doesn't natively support an EditorConfig file, there are plugins available for most other editors.
For Python files, Black, isort, and flake8 are used to enforce code conventions, and Pyright is used for static typechecking. See pyproject.toml in the root of the PrairieLearn repository to view our specific configuration. We encourage all new Python code to include type hints for use with the static typechecker, as this makes it easier to read, review, and verify contributions.
To lint the code, use make lint. This is also run by the CI tests.
To automatically fix lint and formatting errors, run make format.
Question-rendering control flow
- The core files involved in question rendering are lib/question-render.js, lib/question-render.sql, and pages/partials/question.ejs.
- The above files are all called/included by each of the top-level pages that needs to render a question (e.g.,
pages/instructorQuestionPreview,pages/studentInstanceQuestion, etc). Unfortunately the control-flow is complicated because we need to calllib/question-render.jsduring page data load, store the data it generates, and then later include thepages/partials/question.ejstemplate to actually render this data.
-
For example, the exact control-flow for
pages/instructorQuestionis:-
The top-level page
pages/instructorQuestion/instructorQuestion.jscode callslib/question-render.getAndRenderVariant(). -
getAndRenderVariant()inserts data intores.localsfor later use bypages/partials/question.ejs. -
The top-level page code renders the top-level template
pages/instructorQuestion/instructorQuestion.ejs, which then includespages/partials/question.ejs. -
pages/partials/question.ejsrenders the data that was earlier generated bylib/question-render.js.
-
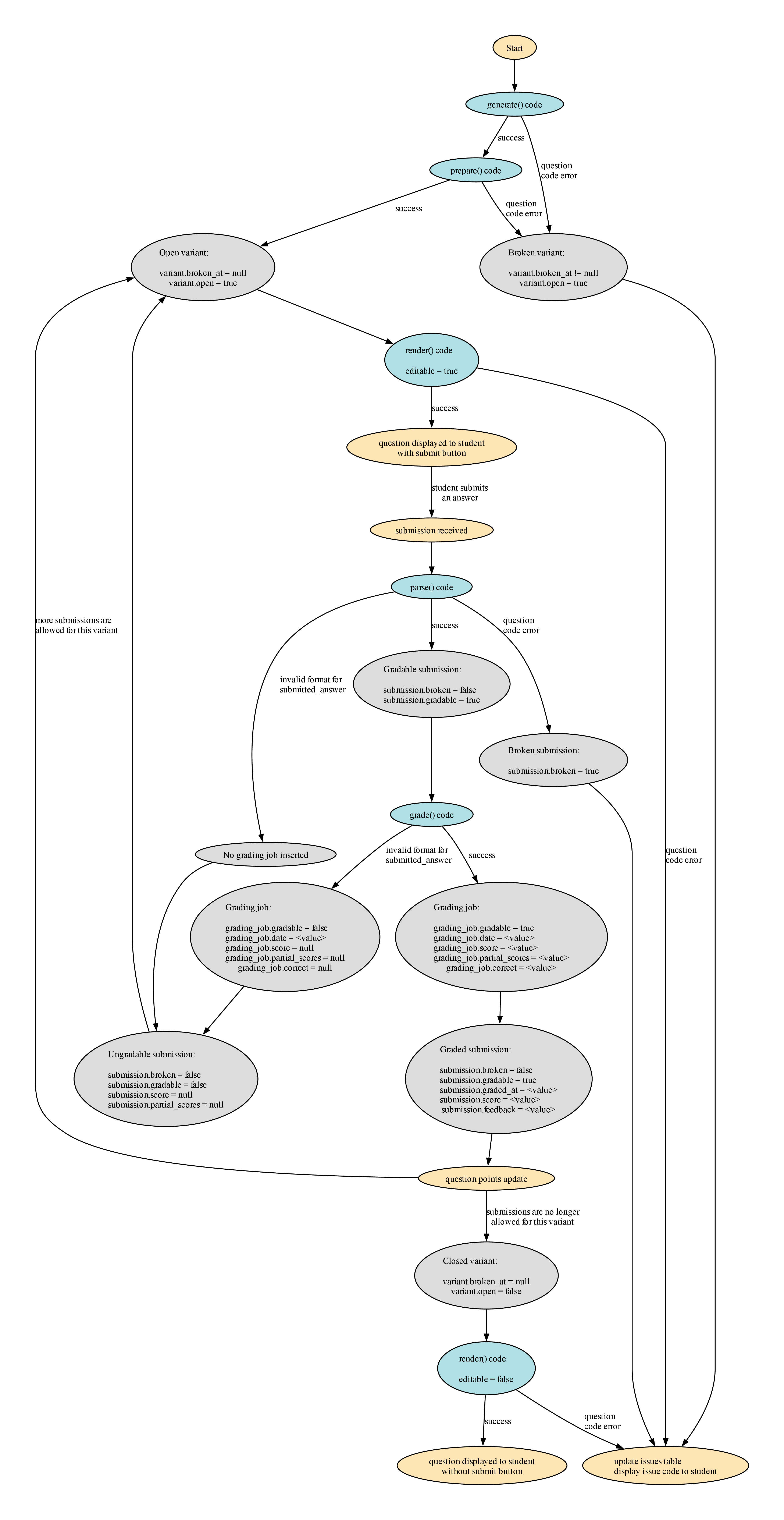
Question open status
-
There are three levels at which “open” status is tracked, as follows. If
open = falsefor any object then it will block the creation of new objects below it. For example, to create a new submission the corresponding variant, instance_question, and assessment_instance must all be open.Variable Allow new instance_questionsAllow new variantsAllow new submissionsassessment_instance.open✓ ✓ ✓ instance_question.open✓ ✓ variant.open✓
Errors in question handling
-
We distinguish between two different types of student errors:
-
The answer might be not be gradable (
submission.gradable = false). This could be due to a missing answer, an invalid format (e.g., entering a string in a numeric input), or a answer that doesn't pass some basic check (e.g., a code submission that didn't compile). This can be discovered during either the parsing or grading phases. In such a case thesubmission.format_errorsobject should store information on what was wrong to allow the student to correct their answer. A submission withgradable = falsewill not cause any updating of points for the question. That is, it acts like a saved-but-not-graded submission, in that it is recorded but has no impact on the question. Ifgradable = falsethen thescoreandfeedbackwill not be displayed to the student. -
The answer might be gradable but incorrect. In this case
submission.gradable = truebutsubmission.score = 0(or less than 1 for a partial score). If desired, thesubmission.feedbackobject can be set to give information to the student on what was wrong with their answer. This is not necessary, however. Ifsubmission.feedbackis set then it will be shown to the student along with theirsubmission.scoreas soon as the question is graded.
-
-
There are three levels of errors that can occur during the creation, answering, and grading of a question:
Error level Caused Stored Reported Effect System errors Internal PrairieLearn errors On-disk logs Error page Operation is blocked. Data is not saved to the database. Question errors Errors in question code issuestableIssue panels on the question page variant.broken_at != nullorsubmission.broken == true. Operation completes, but future operations are blocked.Student errors Invalid data submitted by the student (unparsable or ungradable) submission.gradableset tofalseand details are stored insubmission.format_errorsInside the rendered submission panel The submission is not assigned a score and no further action is taken (e.g., points are changed for the instance question). The student can resubmit to correct the error.
-
The important variables involved in tracking question errors are:
Variable Error level Description variant.broken_atQuestion error Set to NOW()if there were question code errors in generating the variant. Such a variant will be not haverender()functions called, but will instead be displayed asThis question is broken.submission.brokenQuestion error Set to trueif there question code errors in parsing or grading the variant. Aftersubmission.brokenistrue, no further actions will be taken with the submission.issuestableQuestion error Rows are inserted to record the details of the errors that caused variant.broken != nullorsubmission.broken == trueto be set totrue.submission.gradableStudent error Whether this submission can be given a score. Set to falseif format errors in thesubmitted_answerwere encountered during either parsing or grading.submission.format_errorsStudent error Details on any errors during parsing or grading. Should be set to something meaningful if gradable = falseto explain what was wrong with the submitted answer.submission.graded_atNone NULL if grading has not yet occurred, otherwise a timestamp. submission.scoreNone Final score for the submission. Only used if gradable = trueandgraded_atis not NULL.submission.feedbackNone Feedback generated during grading. Only used if gradable = trueandgraded_atis not NULL.
- Note that
submission.format_errorsstores information about student errors, while theissuestable stores information about question code errors.
-
The question flow is shown in the diagram below (also as a PDF image).
JavaScript equality operator
You should almost always use the === operator for comparisons; this is enforced with an ESLint rule.
The only case where the == operator is frequently useful is for comparing entity IDs that may be coming from the client/database/etc. These may be either strings or numbers depending on where they're coming from or how they're fetched. To make it abundantly clear that ids are being compared, you should use the idsEqual utility:
const { idsEqual } = require('./lib/id');
console.log(idsEqual(12345, '12345'));
// > true